
BY: RAHUL ANDHARIA (MSIWM001)
Genomics:
Complete set of genes or genetic material present in cell or an organism is called a genome. Study of this genome is called as genomics. Genomics studies comprises of studying large number of genes through automated tools.
Genomics implies bioinformatics, sequencing methods, mapping methods, computational biology, recombinant DNA technology to study and analyse functions and structures of genomes.
History of Genomics:
Genome sequencing first started in the year 1970, when biochemist Frederick Sanger sequenced the genome for the first time. Virus and mitochondrion genomes were sequenced by Sanger in early 1970s.
Types of genomic studies:
- Structural Genomics: It involves gene identification, construction of genetic and physical maps, annotating gene function and comparison of genome structures. It involves determining structure of each and every protein encoded by genes.
- Functional Genomic studies: understanding of how genes and intergenic regions of genome contribute to various biological processes. It also deals with the study of individual components of body and how it affects the phenotype. For example- functional genomics is useful in studying the dynamic expression of diseased genes.
- Comparative genomics: it is the comparison of genomes of different organisms. Basically it includes gene number, gene content and gene location comparison. The comparison between various genomes provides insight on conservation of different genomes and how the genome is being evolved in a particular organism. This can also useful in genome evolutionary studies among various species.

- Mutation genomics: deals with studying the genome in terms of mutation that is it involves studying mutated genes and it’s effects and how gene mutations leads to diseases.
Methods in Genomics:
Genome mapping:
- Mutations, relative locations in genes and traits on a chromosome can be identified by using genome mapping.
- In this method, a particular gene is located or assigned at a particular position in the chromosome and than relative distance between the gene and the chromosome is mapped.
- Linkage maps- It shows how genes and genetic markers are arranged in a chromosome.
- Physical maps- It will show the physical distance between chromosomal landmarks and generally, physical maps represents a chromosome. The distance is measured usually in nucleotide bases.
Genome sequencing:
- To sequence a genome, it is important to figure out the exact order of DNA nucleotides or bases. (A,T,G,C bases).
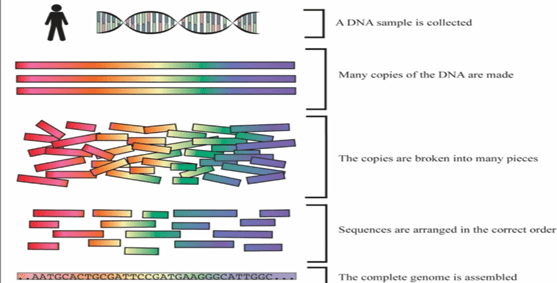
- Sequencing the entire genome is a cumbersome task. The process involves breaking the DNA of genome into smaller pieces first, than sequencing those each and every pieces and those pieces are than assembled as a single long consensus ( sequence with similar function and structure)
- The DNA sequencing method in today’s modern era is very rapid and hence provides whole genome sequencing of various genomes of different species, which is instrumental in studying various diseases and evolutionary forms of life.
Genome sequence assembly:
- Short sequence reads are generated from DNA clones.
- These reads are around 500bases. Short sequence reads are joined together to form larger fragments after removing overlaps to assemble a whole genome sequence.
- These new long sequences can be called as coting’s. They are around 5000-10,000 bases long.
- Scaffold is formed from many number of overlapping contigs.( Oriented along a chromosome).
- These scaffolds are than connected to make a final genome map.
- Generally, computational tools are required to identify correct contigs and proper assembly of sequence reads.
- Some common examples of assembly programs are Vecscreen, Phred, Phrap, TIGR assembler.
Genome annotation:
- To analyse sequence for biological features before depositing it into the database, comments are provided for the sequences, which is called genome annotation.
- Gene prediction and function assignment are the two types in annotating genomes which can be done using bioinformatic tools.
Human genome project: (HGP):
One of the most successful projects in scientific discovery, HGP was a major breakthrough, where scientists mapped the complete sets of genes, together called a genome. The HGP project was started in 1990 and completed in the year 2003. This was the first of its kind project that gave us the genetic blueprint for building a human being.
Applications of Genomics:
- Can be used in prenatal diagnosis.
- To analyse gene expression profiles of organisms.
- To identify diseased gene.
- Gene therapy –( defected gene is replaced by correct gene) used particularly to treat Genetic disorders.
- Genome editing ( to replace sections of DNA sequences, or to edit a particular sequence).
Proteomics:
It is the study of complete set of proteins expressed by the genome.(study of functions of proteomes) Set of complete proteins encoded by a particular genome can be called as a Proteome. This includes basically studying in depth about Protein-Protein Interactions, protein modifications and how a particular protein functions in different organisms.
History of proteomics:
Proteomics is still evolving as a field and is considered as a relatively new field of molecular biology. The history of proteomics dates back to 1995, when Mark Wilkins, for the first time coined the term proteome. There are around 400,000 proteins founded in human proteome than number of protein coding genes, which was one of the major findings of the Human genome project.
First protein studies were carried out in E.coli using 2 dimensional gel electrophoresis by O’Farrell in the year 1975.
Types of proteomic studies:
- Expression proteomics- it involves studying gene expression between samples that differ by some variable. This can be useful in identifying particular proteins involved in disease.
- Structural proteomics- it involvesstudying structure and nature of protein complexes. It involves studying and analysing Protein-Protein Interaction networks.
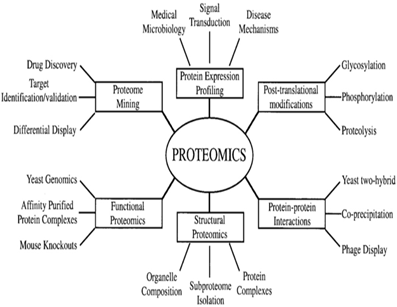
- Functional proteomics: in this role of a particular protein or group of proteins is studied in different cellular pathways, signalling pathways and in PPI networks.
Categories for designing typical proteomics experiment: ( methods used for proteomics)
- Isolation and protein separation- By using protein electrophoresis, complex mixtures of proteins can be resolved.
- Acquiring protein structural information for identification and characterization of protein-
ES sequencing( Edman sequencing):
- This sequencing was done to identify N-terminal sequences of protein.
- It involves determining the sequence of N-terminal of a protein in order to predict it’s start site.
- Proteins separated by SDS page can be more efficiently analysed by ED sequencing.
- Major limitation with this technique is, we cannot modify the N-terminal of protein. For example, if a protein is blocked on the N-terminal, before the sequencing procedure, it will be very difficult to identify that protein.
Mixed peptide sequencing:
- Cyanogen bromide is used to cleave protein to convert it to a peptide.
- This is followed by ED sequencing.
Mass spectrometry:
- Can identify gel separated proteins.
- Sensitivity levels are very high in mass spectrometry, and that is the reason, this technique is preferred more over ED sequencing.
- In the gel by using, trypsin, proteins are digested into peptides.
- ESI(electrospray ionisation): in this approach of mass spectrometry, the peptides are fragmented and than ionised by using an electrospray in a tandem mass spectrophotometer. Sample flows from microcappillary tube to orifice, due to potential difference between the two, it results in generation of fine droplets. This has the ability to dissociate into carboxyl terminal, which gives fragments a and b.
Peptide mass mapping:
- Eluted peptide mixture is used to obtain mass spectrum of the peptide eluted. This is followed by studying the peptide mass finger print resulting from the peptide spectrum.
- In this method, as trypsin cleaves proteins at arginine and lysine amino acid, tripeptide mixtures are generally analysed in peptide mass mapping.
Protein databases and utilization:
- Submission of sequences and sequencing proteins or peptides leads to creation of protein assembly which are called as Protein data bases.
- The database contains all the basic protein data.
- The main aim of creating such database is to have accurate and quick results and to store information at one place.
Applications of proteomics:
- Studying gene expression profiles of various proteins.
- To analyse Protein-Protein Interactions- how one protein interacts with other proteins and leads to changes or alterations, it’s expression and level of expression.
- To study post-translational modifications like glycosylation and phosphorylation.
- Molecular medicine- clinical proteomics information is used to design drugs. Proteins are considered as medical relevance for this studies and are used as targets to study their role in disease progression, and to develop better therapeutics.

One thought on “GENOMICS AND PROTEOMICS”